Building software to prioritise and resolve issues in smart warehouses
Ocado Technology builds intelligent automation systems that integrate AI and robotics to power smart warehouses with minimal human intervention.

Overview
The Ocado grid powers its automated fulfilment system and any downtime can cause delays, inventory issues, and failed deliveries, affecting both Ocado and its retail partners. A team of Grid Operators monitor the autonomous hardware, diagnose faults, and resolve issues remotely.

Challenge
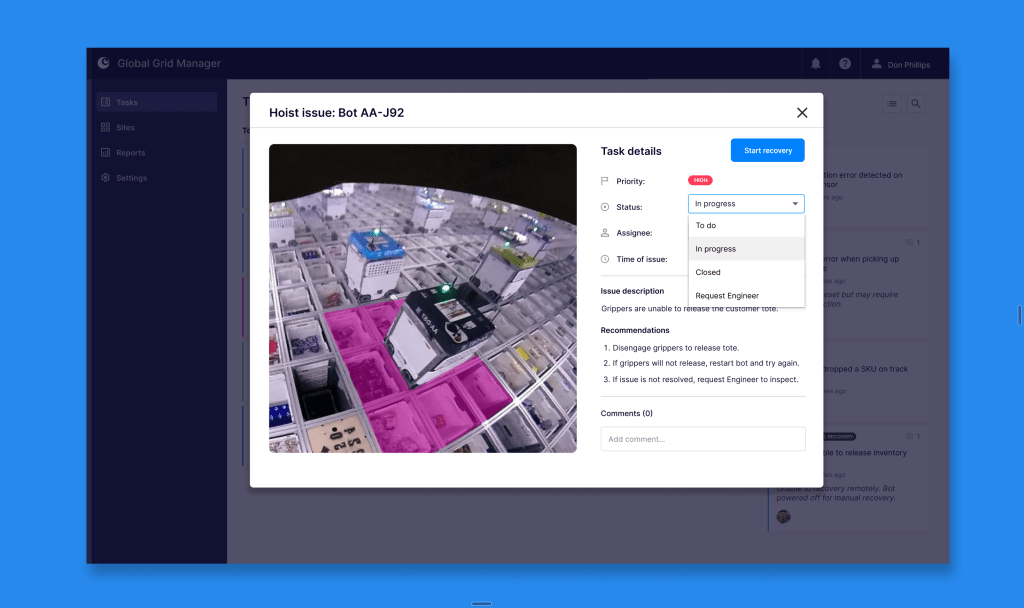
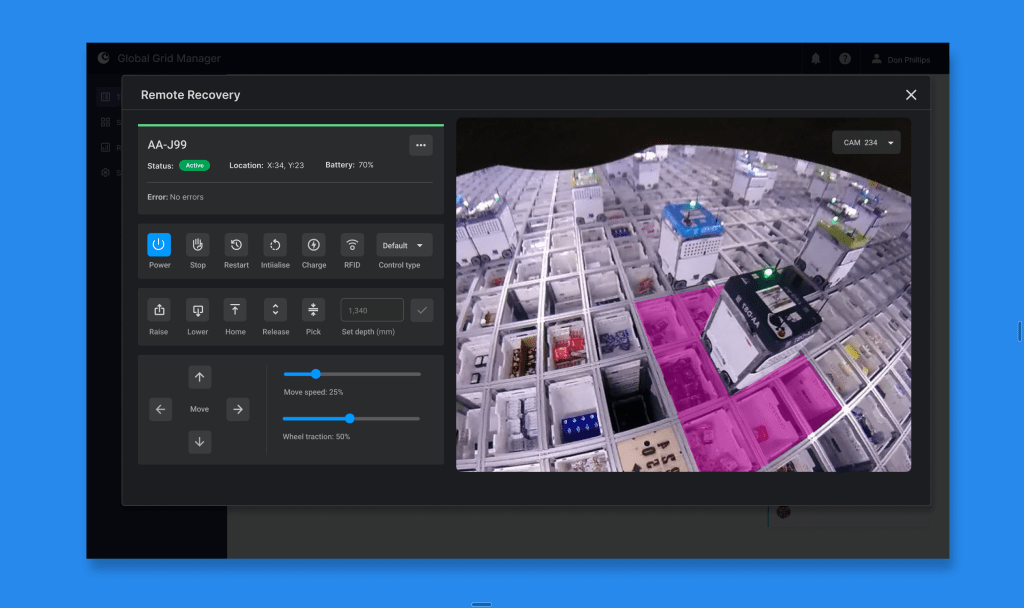
Grid Operators were required to use a fragmented set of tools to identify and resolve robotic issues. A key dependency was an outdated CLI tool used to remotely connect to recover robotic hardware that had gone into error and send recovery commands. The Remote Recovery application had a steep learning curve and a high risk of user error that often led to critical service disruptions and costly recovery procedures when mistakes occurred.

Project goals
- Build a GUI based application that provides all the features to remotely resolve robotic hardware issues
- Reduce the time taken to resolve an issue
- Reduce the number of human errors during recovery process
- Reduce training cost and learnability
Project team
I worked as the sole UX designer across three separate product teams—one based in England and two in Bulgaria—each comprising a Product Owner, Engineering Lead, and Software Engineers. I was responsible for the end-to-end UX including user research, analysis, ideation, prototyping, and design. I collaborating closely with all teams across time zones to co-engineer and deliver real time product solutions.
Research activities
To understand the complex operational landscape of Ocado’s global warehouses, I conducted field studies at various sites around the world. This involved observing and interviewing both Grid Operators and Engineers as they performed their daily tasks, to understand goals, motivations, challenges and workflow between teams and any differences across warehouse locations.
I mapped user workflows across these international sites to capture a comprehensive view of how remote recovery tasks were executed, identify regional variations, and uncover operational pain points. To deepen my understanding, I undertook the full two-day training programme provided to new starters. This hands-on experience gave me a solid foundation in how the tools are used to identify, diagnose and resolve robotic issues.
A data review of the issues and the respective resolution paths when users carried out remote recovery tasks across the different sites was also undertaken. This enable the identification of incident types, incident volume, resolution and failure paths, resolution time and error metrics.


Key research findings:
- Inconsistent Recovery Practices: There was a lack of standardisation across sites in how common incidents were resolved, leading to inefficiencies and varied outcomes.
- Steep learning curve: While experienced users were comfortable with the technical interface, new users struggled and desired a more intuitive, less technical experience. Managers commented that this was affecting the retention of staff as the initial learning curve was very high.
- Manual prioritisation of issues: Operators were required to use a number of different systems to identified the different issues that needed to be resolved and then manually prioritise based on their experience. This process led to a very inefficient task workflow and important tasks being overlooked for smaller tasks.
- Automation opportunities: Analysis of the successful recoveries showed a clear pattern of commands submitted which highlighted opportunities for the automation of some recoveries. The automation of commands could enable the system to attempt to resolve the issue before escalating to the human operator.
- Command Redundancy: Over 30% of the application’s commands were redundant, providing opportunities to reduce the number of commands required for the new application.
- Hoist-Related Incidents: Hoisting issues accounted for 80% of all recoveries. From a business perspective it was also the most costly, due to the complex hoisting mechanisms. This highlighted a critical area for improvement.
Design sprint
I led a four-day Design Sprint with Product Managers, Engineers, and Grid Operators that allowed us to rapidly surface insights, align stakeholders, and accelerate key decisions. Working closely with the teams, we addressed the following challenges:
- Identifying and resolving any technical barriers for Engineering teams.
- Identifying additional safety measures to reduce number human related errors.
- Identified opportunities to reduce recovery time by streamlining key process steps.
- Agreeing on the core requirements for a new remote recovery application
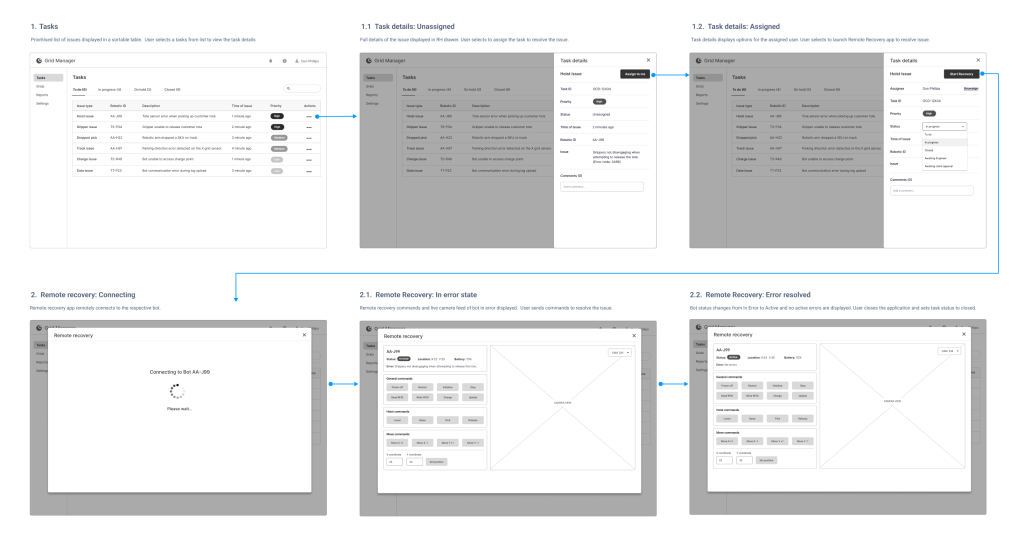
- Designing a task management workflow to support issue prioritisation, assigning tasks, escalation and resolution paths.


User testing
Based on the agreed task management workflow and the key features identified for the remote recovery application, I designed a clickable prototype, which I validated through a combination of on-site and remote user testing sessions, as well as focus groups with Grid Operators and Engineers across multiple global sites. The testing tasks focused on the most common issue types and explored different possible outcomes—from successful recoveries to escalating issues to Engineering teams for manual intervention.

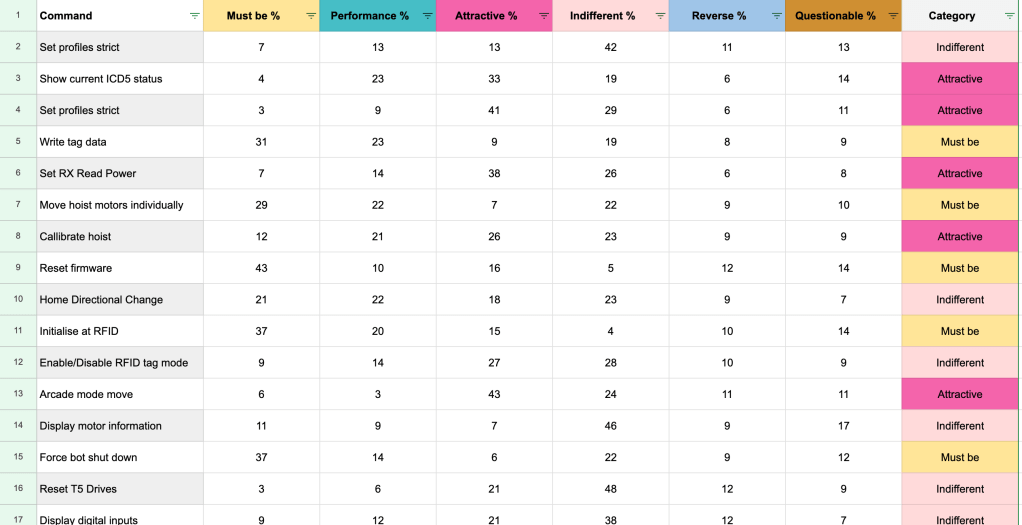
To complement qualitative feedback, I also ran two structured rating exercises. The first was a set of statements about the user’s experience with the prototype, each rated from Strongly agree to Strongly disagree (e.g., “The product has all the features I need to do my job effectively”). The second was a prioritisation exercise, where users rated each feature and command in the application on a scale from Not important to Extremely important.
Overall, the prototype was well received and generated a lot of excitement and anticipation of the upcoming product. However, the results revealed differences between sites and experience levels, which further investigation. I scheduled follow-up interviews with users who had given lower ratings to better understand their concerns and explore ways to improve their experience.
Prioritisation of features
To shape the roadmap and prioritise future iterations more effectively, I applied the Kano Model to analyse user feedback and categorise features:
- Must-have features – The essential functions users expect to meet their basic needs. Without these, the product would be considered incomplete. For example: the ability to restart the hardware.
- Performance drivers – Features that have a direct, proportional impact on satisfaction – the better they perform, the more satisfied users are. For example: faster connection and response speed.
- Delighters – Unexpected features that aren’t necessarily missed if absent, but create disproportionate satisfaction when present. For example: automation of repetitive commands.
Beta product release
After several rounds of refinements, a beta version of the product was released for testing in a controlled environment. The initial focus was on resolving hoist-related issues—which accounted for 80% of all incidents—before gradually introducing support for other issue types.
To drive continuous improvement, we established a robust feedback loop that included site visits, user surveys, user testing sessions and the comparative ratings questionnaire used during the prototyping stage. To ensure feedback could be gathered outside of these touchpoints, a spreadsheet was created to allow users could log and issues they encountered and also highlight any improvements and recommendations for the product. A channel in Slack was created to provide real time support for users and was also used as a ‘news’ channel to raise awareness of upcoming features, share insights and celebrate successes. This direct connection with users allowed us to respond quickly to feedback and iterate at pace and build a strong relationship with our users.
Measuring performance
The key success metrics for the product was to reduce the time it takes to remotely resolve robotic issues and to reduce the numbers of human errors. Performance data was measured and tracked against the existing recovery process, with additional segmentation by shift team and experience level (novice vs. experienced users).
Live trial results showed a 25% decrease in issue resolution time and a 50% reduction in human-related errors. The main contributors to these improvements were:
- Single, prioritised task list that aggregated all issues, eliminating the need for users to manually locate and prioritise tasks—improving focus and response times.
- Integrated task flow enabling users to connect to the hardware in error with a single click, reducing connection time. When manual intervention was required, tasks could be sent directly to an Engineer, further improving response times.
- Depth detection when manually lowering the hoist, reducing hoist-related errors during recoveries.
- Automatic safety barriers when moving the bot, preventing crashes and reducing track-related issues.
- Automated resolution of common issues by the system, reducing the number of tasks presented to users and streamlining workflows.
The results were highly encouraging, giving the business the confidence to roll the product out to additional warehouse sites. With each deployment, we refined the user experience based on insights, introducing new features, improving the UI, and addressing technical challenges.
Outcome
The product was successfully rolled out to all warehouses globally, transforming the management of robotic incidents across Ocado’s smart warehouses. It reduced training time, enhanced safety and accountability, and improved operational efficiency—cutting incident resolution time by 20% and reducing user errors per recovery by nearly 60%.